
Introduction
In today’s data-driven world, the ability to extract relevant information from vast amounts of data is crucial. Traditional LLMs often fall short when faced with queries for which they have not been specifically trained. This is where RAG (Retrieval Aaugmented Generation) comes into play, offering a solution to enhance the capabilities of LLMs and enabling them to provide responses based on information they have not been explicitly trained on.
Retrieval Augmented Generation is also an innovative approach in natural language processing that combines the strengths of both retrieval-based and generative models. Traditional methods often struggle with generating coherent and contextually relevant responses, while retrieval models excel at extracting information from a vast knowledge base. RAG seeks to bridge this gap by integrating these two paradigms.
For example
User: What is the revenue of the company this year
LLM: Sorry, I don’t have enough information about this
User: what is langchain
LLM: As of my last knowledge update in January 2022, I don’t have specific information about “LangChain.” It’s possible that there have been developments or new information about LangChain after that date.
User: suggest me the train to visit delhi
LLM: I don’t have the capability to book or suggest specific train tickets, as I’m a text-based AI model and do not have real-time internet access.
Human raters discovered that responses generated by RAG are approximately 43% more precise compared to answers produced by an LLM utilizing fine-tuning methods.
Limitations of LLM
When posed with queries outside their training scope, LLMs typically lead to hallucinations and respond with either a lack of information or incorrect output despite the data potentially being available in proprietary or public datasets. For businesses, this limitation can hinder their ability to extract valuable information and make informed decisions based on comprehensive data.
LLM models have a few issues, such as a knowledge cut-off date and answers from data until they can be trained, can not provide real-time data analysis, or even do not have access to private sensitive data.
Augmenting Large Language Models
The goal of retrieval-augmented generation is to expand the scope of LLMs’ knowledge, enabling them to respond to queries using information that may not have been part of their original training data. This is achieved through a two-step process involving retrieval and generation, allowing LLMs to provide responses that surround a broader context window than traditional models.
Implementing Retrieval Augmented Generation
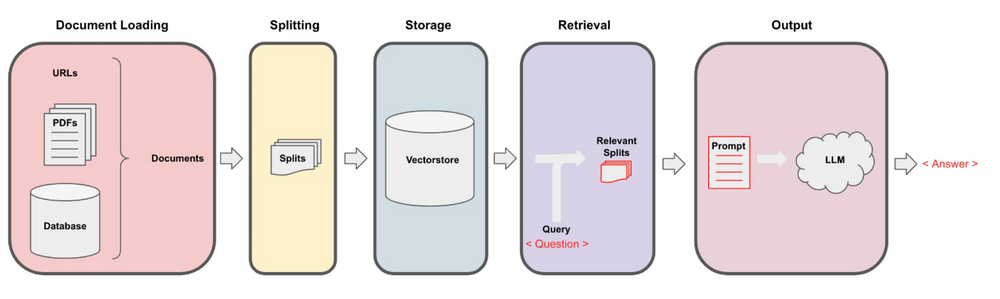
Image Source: https://blog.langchain.dev/building-llm-powered-web-apps-with-client-side-technology/
To implement RAG, a technique known as Lang chain, an open-source framework, can be utilized. This framework offers the necessary tools and APIs to simply the process of integrating LLMs with external data sources, driving AI applications that can efficiently leverage RAG. Load the documents from various sources such as PDFs, sets of videos, URLs, etc. Splitting the large documents into smaller chunks of data
Vector store Embeddings
The central process of RAG is the use of vector embeddings, which serve as a means of storing and retrieving complex, high-dimensional data in a more manageable format. The retrieval stage involves searching through a database of pre-compiled vector embedding to find the most relevant information based on the user query, while the generation stage utilizes this retrieved information to prompt the LLM to generate a response.
Create a retriever for querying the vector store database.
Leveraging Lang Chain
Lang chain acts as an orchestrator, for AI developers to seamlessly integrate LLMs with external data sources and computation, thereby facilitating the implementation of RAG-driven applications. Available in both Python and JavaScript libraries, the Langchain simplifies the process of harnessing the power of RAG within enterprise environments.
Conclusion
Retrieval augmented generation represents a significant advancement in the capabilities of large language models, enabling them to provide responses that are more contextually relevant and comprehensive. By leveraging RAG techniques and frameworks such as lang chain, businesses can harness the power of their proprietary data to drive informed decision-making and extract valuable insights from their enterprise data.
Retrieval Augmented Generation stands as compelling advancements in natural language processing, seamlessly integrating the precision of retrieval models with the creative capabilities of generative model craft responses based on this context, RAG addresses the limitations of traditional approaches.
FAQs
RAG is applied in question-answering systems, chatbots, and content creation platforms. RAG offers a versatile framework for integrating retrieval-based and generative methods in natural language processing tasks, leading to more accurate, relevant, and contextually rich outputs.
RAG's adaptability stems from its utilization of fine-tuned retrievers tailored for specific tasks and ongoing exploration of advanced architectures like dense retrievers, amplifying its performance across diverse domains.
RAG involves a two-stage process. First, a retriever extracts relevant information from a knowledge base. Then, a generative model crafts responses based on this extracted context, leveraging the precision of retrieval systems and the creativity of generative models.


