
Series Prompting Technique
- First, break the prompt into multiple sequential prompts.
- We see that this technique allows outputting more structured and informative results by avoiding irrelevant information in the output.
Example – Say you want to write a blog on music therapy and its benefits.
So, the way you achieve this is simple – you prompt the AI in steps to write the introduction, then the body, and finally, the conclusion. The output from the first prompt is used as input to the second prompt. This cycle just goes on.
Parallel Prompting Technique
- This involves breaking your prompt into chunks and then combining them.
- This technique outputs very diverse and interesting results
- You can use it to get different tones and styles in one combined output.
Example – You want to write a blog on art and its benefits. So you’d ask the language model these:
Chunk 1: “Write a brief history of drawing.”
Chunk 2: Explain the different methodologies in art.
Chunk 3: Discuss the psychological benefits of art.
Chunk 4: Share fun anecdotes about the impact of art.
And then combine them with another prompt.
Looping Prompting Technique
This technique is used by repeatedly requesting the same prompt multiple times until you get the desired result, each time asking AI to do/add an extra bit.
It can be used in combination with Series and Parallel Prompts for better results.
Example –
- You give the AI a prompt to write an introduction to music and its benefits.
- The output provided is an introduction to music and highlights some of its benefits, such as stress reduction and improved mood. You can again give a prompt to add more benefits till you get the desired output.
Chain-of-Thought (CoT)
Greedy CoT is a traditional method that was previously used by Amazon Bedrock until very recently (2023).
This prompting enables even the most complicated reasoning capabilities through intermediate reasoning steps.
- You can combine it with a couple of few-shot prompts.
- This then gives better results on more complex tasks that require reasoning before responding.
Example –
Prompt: The odd numbers in this group add up to an even number: 4, 8, 9, 15, 12, 2, 1.
AI Output: Adding all the odd numbers (9, 15, 1) gives 25. The answer is False.
Self-Consistency Prompting
Self-consistency prompting is the method currently used by Amazon Bedrock. It is used to improve the performance of generative language models.
The techniques use a huge variety of stochastic decoding to achieve this goal in three steps:
- The technique is used to prompt the language model with CoT examples to elicit reasoning.
- This can completely replace greedy decoding with sampling strategies to generate a diverse set of reasoning paths.
- Aggregate the outputs to find the most consistent answer in the response set.
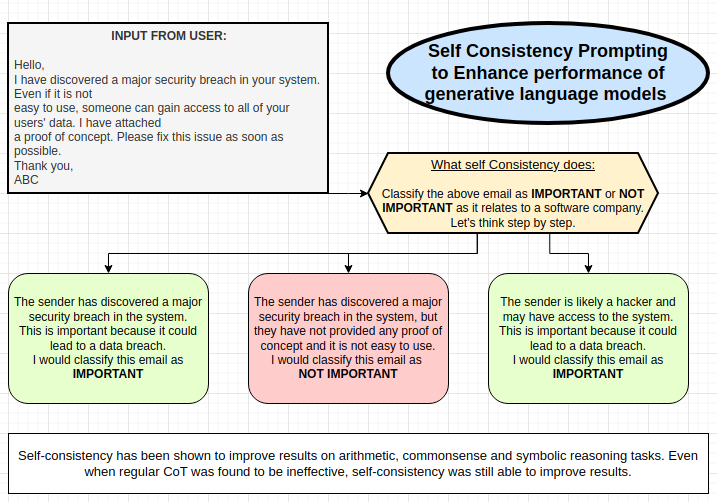 Fig. 1
Fig. 1
To implement self-consistency prompting on Amazon Bedrock:
- Choose the foundation model that best suits your needs and download an AWS account with a sagemaker-hosted notebook instance.
- Access the batch inference API provided by Amazon Bedrock to run inference efficiently.
- Incorporate self-consistency prompting into your workflow by generating multiple responses for a given prompt using stochastic decoding strategies.
- Upload import data to Amazon S3.
- Aggregate responses using the sample-and-marginalize procedure for enhanced consistency and reliability.
- Finally, try to evaluate the performance of your enhanced generative language model very effectively using self-consistency prompting. You can use Sagemaker for this.
 Fig.2
Fig.2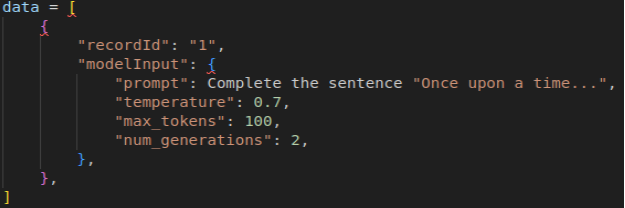 Fig. 3
Fig. 3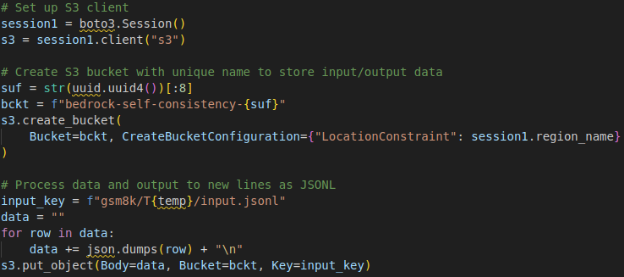
Fig.4
Fig.5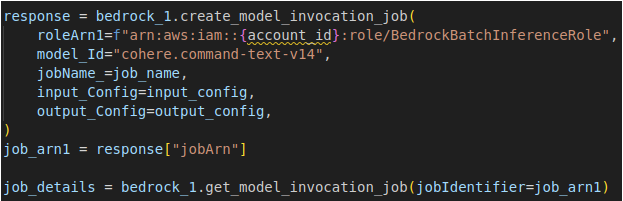
Fig.6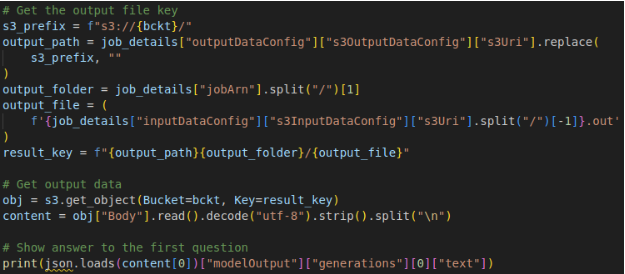
Fig.7


